article detail
누스 리서치, ‘토큰 중첩 학습’으로 사전훈련 시간 2.5배 단축
2026. 5. 17. 오후 6:20
AI 요약
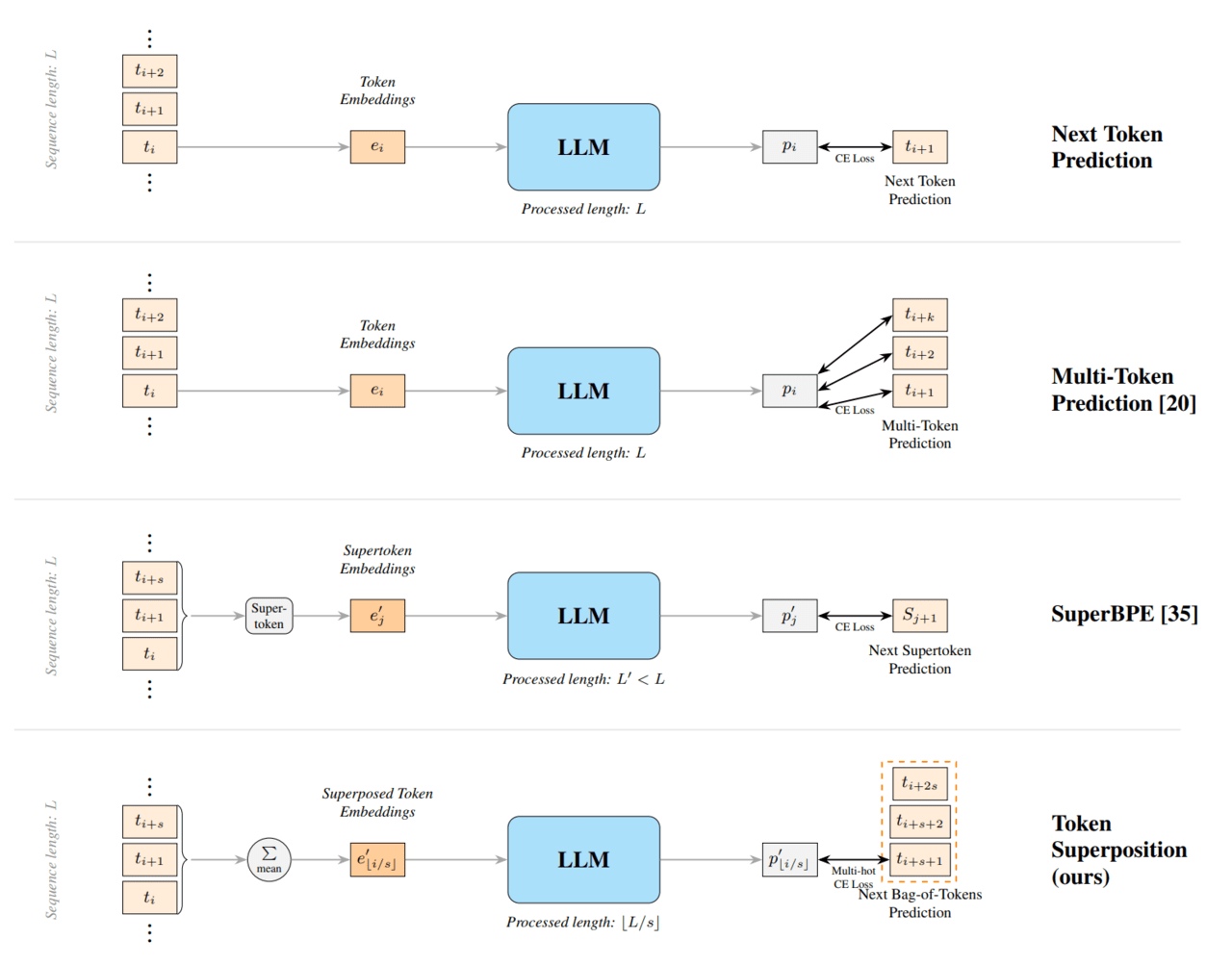
미국 AI 연구조직 누스 리서치는 모델 구조를 바꾸지 않고 사전학습 시간을 단축하는 '토큰 중첩 학습(TST)'을 공개했으며, 이 기법은 여러 토큰을 묶어 초기에는 압축해 학습한 뒤 복구 단계에서 개별 토큰을 예측하는 2단계로 동작하고 모델 아키텍처·옵티마이저·토크나이저 등을 변경하지 않는 드롭인 방식이며 동일한 연산량(FLOPs)을 유지한다고 설명했습니다. 연구진은 270M·600M·3B·10B-A1B MoE 등 다양한 규모에서 검증했고, 10B-A1B 실험에서는 기존 대비 약 2.5배 빠른 사전학습 속도를 기록했으며 표준 방식이 1만2311 B200 GPU-시간이 필요했던 반면 TST는 4768 GPU-시간만으로 더 낮은 최종 손실(2.236 대 2.252)과 HellaSwag·ARC·MMLU 등 벤치마크에서의 우수한 성능을 보였다고 발표했습니다. 다만 동일 데이터 소비량(equal-data) 기준에서는 기존 방식이 더 높은 성능을 기록했으며 연구진은 이를 TST 적용 범위를 결정하는 중요한 경계 조건으로 제시했으며 업계에서는 TST가 LLM 개발 비용 구조를 바꿀 가능성이 있다고 평가했습니다.


![[테크스냅] KT, 'XL-세이프티벤치' 벤치마크 공개 — IT뉴스모아](https://img8.yna.co.kr/etc/inner/KR/2026/06/04/AKR20260604093600017_01_i_P4.jpg)


![[테크스냅] AI PC서 GPU·NPU 분산 활용…노타, LLM 추론 효율 높인다](https://news.nateimg.co.kr/orgImg/yt/2026/06/04/AKR20260604065000017_01_i.jpg)
![[AI 브리프] NC AI, 한화오션 상선·특수선에 ‘자율 용접 로봇 AI 두뇌’ 공급](https://cdn.itdaily.kr/news/thumbnail/202606/239652_244883_1012_v150.jpg)
![[테크스냅] AI PC서 GPU·NPU 분산 활용…노타, LLM 추론 효율 높인다](https://thumbnews.nateimg.co.kr/view610///news.nateimg.co.kr/orgImg/yt/2026/06/04/AKR20260604065000017_01_i.jpg)
