article detail
'공포' 타이틀 달고 돌아온 '터보퀀트' [AI 딥다이브]
2026. 4. 6. 오후 9:01
!['공포' 타이틀 달고 돌아온 '터보퀀트' [AI 딥다이브]](https://thumbnews.nateimg.co.kr/view610///news.nateimg.co.kr/orgImg/me/2026/04/03/news-p.v1.20260403.ad2601f0dc9d47489268ca27b7a33358_P1.jpg)
AI 요약
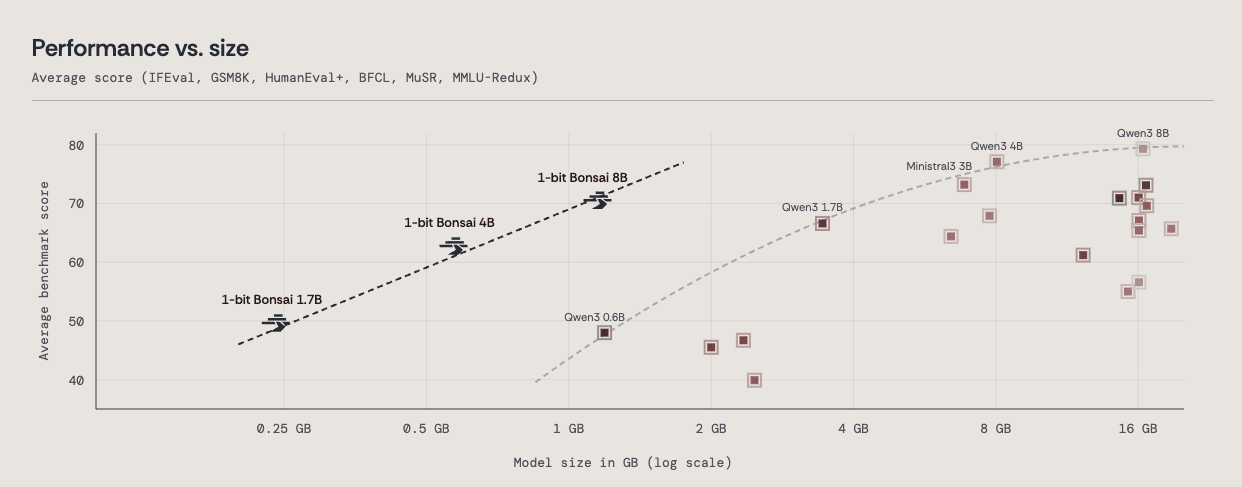
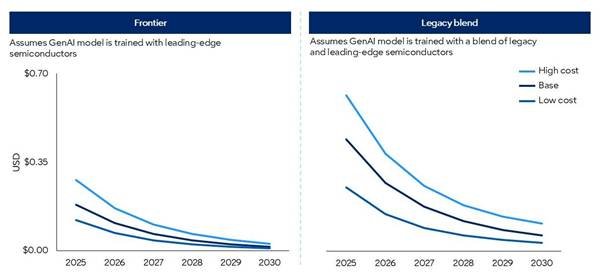
구글의 터보퀀트는 LLM 추론 시 쌓이는 KV 캐시를 16비트에서 3~4비트 수준으로 압축해 메모리 사용을 줄이고 일부 구간에서 속도를 높이는 양자화 알고리즘으로, 본질적으로 기존 양자화 기법의 연장선이며 1년 전 공개된 기술입니다. 현장에서는 이미 FP8·FP4 수준 최적화가 쓰이고 있어 구글이 언급한 6배 개선폭은 실제로는 2~3배(한종목 애널리스트는 약 2.7배) 수준이며, 딥시크의 MLA(Multi-head Latent Attention)처럼 구조 재설계로 28배 압축한 사례도 있어 터보퀀트를 완전한 혁신(제로 투 원)으로 보지 않습니다. 애널리스트들은 메모리 효율 개선이 비용을 낮춰 AI 활용과 수요를 더 확대할 수 있다는 제본스 역설을 근거로 HBM·고용량 D램·기업용 스토리지의 전략적 가치가 오히려 높아지고 반도체 수요가 유지될 가능성이 높다고 평가합니다.

![‘공포’ 타이틀 달고 돌아온 ‘터보퀀트’ [AI 딥다이브]](https://img1.daumcdn.net/thumb/S1200x630/?fname=https://t1.daumcdn.net/news/202604/06/mkeconomy/20260406210304055qmkv.jpg)

![[매경의 창] LLM 혁명의 새 슈퍼갑 '메모리'](https://thumbnews.nateimg.co.kr/view610///news.nateimg.co.kr/orgImg/mk/2026/04/09/20260410_01110130000005_M00.jpg)