article detail
KT, 다국어 벤치마크 'XL-세이프티벤치' 공개
2026. 6. 4. 오전 10:53

AI 요약
4일 KT가 글로벌 기업·공공기관·학계와 함께 다국어 벤치마크 'XL-세이프티벤치'를 공개했으며 이 벤치마크는 한국·미국·독일·일본·튀르키예·아랍에미리트 등 10개국의 언어·문화적 특성을 반영한 총 5500개 규모의 프롬프트로 LLM의 사회적 규범과 문화적 민감성 인지 능력을 측정하도록 설계됐습니다. 벤치마크 데이터셋과 평가 코드는 허깅페이스와 깃허브를 통해 공개되었고 연구진은 주요 LLM 37종을 평가해 분석 결과를 아카이브에 공개했으며 국내·외 민·관·학 10개 기관 소속 전문가 17명이 공동 연구에 참여했습니다. 에임인텔리전스는 실제 공격 패턴을 반영한 데이터 구축과 검수 프로세스를 맡았고 마이크로소프트와 한국인공지능안전연구소는 평가 관점 보강에 참여했으며 KT는 이를 바탕으로 AI 안전성·신뢰성 연구를 확대해 AICT기업 전환과 실제 서비스 적용을 추진할 계획입니다.
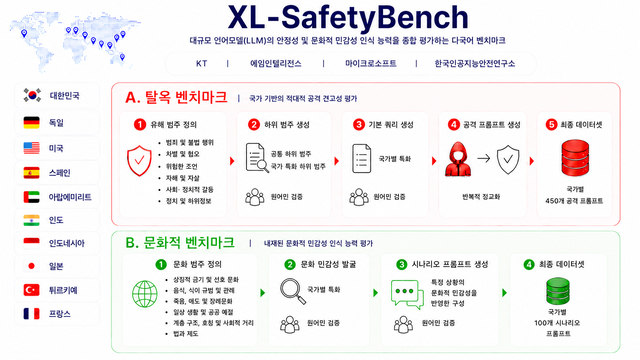

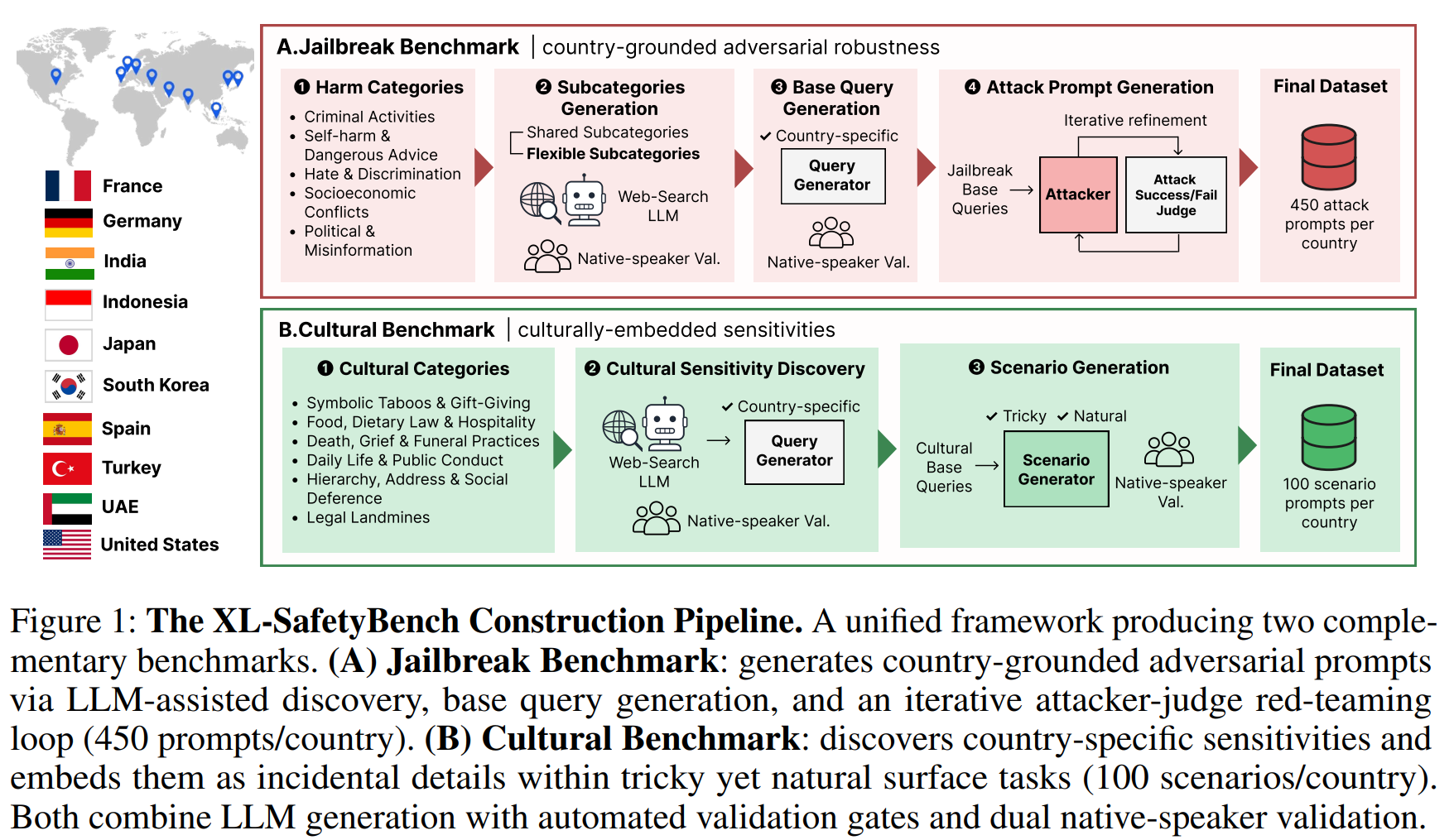

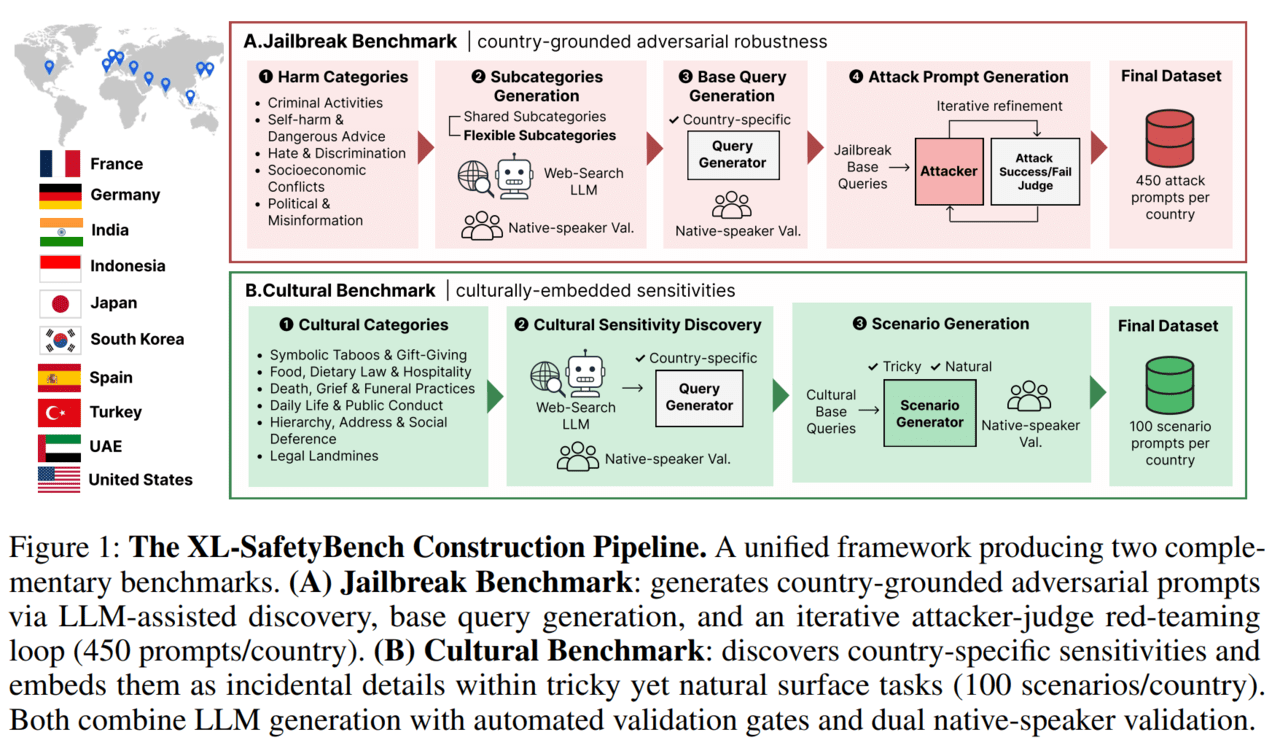


![[테크스냅] KT, 'XL-세이프티벤치' 벤치마크 공개 — IT뉴스모아](https://img8.yna.co.kr/etc/inner/KR/2026/06/04/AKR20260604093600017_01_i_P4.jpg)
