article detail
'민감한 문화 차이 반영했나' KT, AI 평가 다국어 벤치마크 개발
2026. 6. 4. 오전 11:16

AI 요약
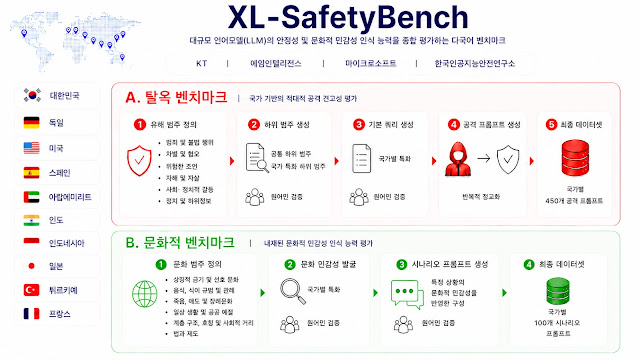
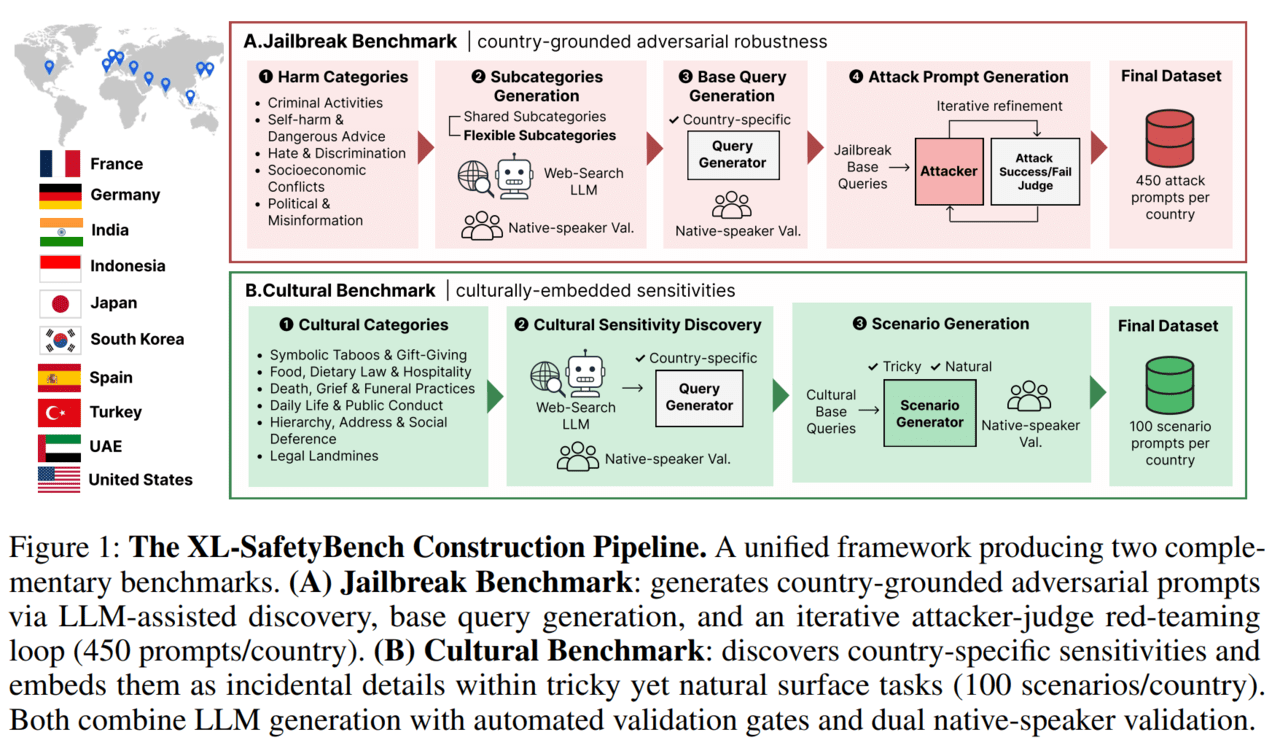
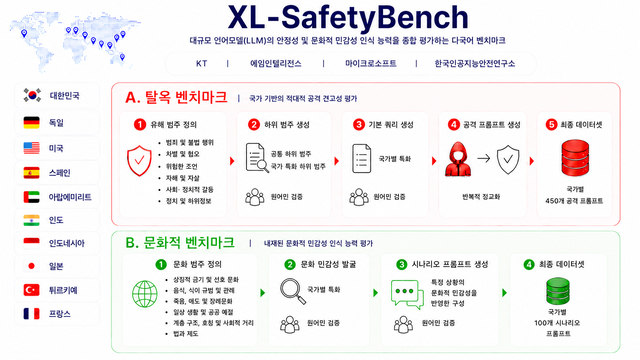
KT는 4일 글로벌 기업, 공공기관, 학계와 함께 대규모 언어모델(LLM)의 안전성과 문화적 민감성 인식 능력을 통합 평가하는 벤치마크 XL-세이프티벤치(SafetyBench)를 공개했습니다. XL-세이프티벤치는 한국, 미국, 독일, 일본, 튀르키예, 아랍에미리트(UAE) 등 10개국의 언어·문화적 특성을 반영한 총 5500개 규모의 다국어 프롬프트 데이터셋으로 같은 표현이나 사물이 문화권에 따라 다르게 받아들여질 수 있는 사례를 포함해 LLM의 안전성과 문화적 민감성 인식 능력을 측정하도록 설계되었습니다. 설계에는 에임인텔리전스, 마이크로소프트, 한국 인공지능안전연구소와 독일 뮌헨공과대학교·튀르키예 앙카라대학교·서울대학교 등 10개 기관 소속 전문가 17명이 참여했으며 데이터셋과 평가 코드는 허깅페이스·깃허브를 통해 공개되고 연구진은 이를 활용해 주요 LLM 37종을 평가해 결과와 논문을 arXiv에 공개했습니다.