article detail
LG, 멀티모달 AI ‘엑사원 4.5’ 공개…문서·이미지 통합 이해
2026. 4. 9. 오전 11:02

AI 요약
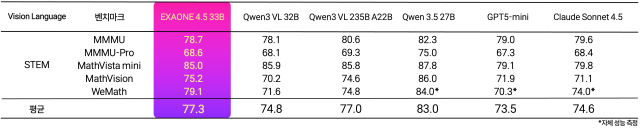
LG AI연구원이 텍스트와 이미지를 동시에 이해·추론하는 멀티모달 인공지능 모델 '엑사원(EXAONE) 4.5'를 공개했으며, 비전 인코더와 거대언어모델을 통합한 비전-언어 모델(VLM) 구조로 계약서·기술 도면·재무제표·스캔 문서 등 복합 문서 분석에 강점을 보입니다. 벤치마크 결과 엑사원 4.5는 STEM 5개 지표 평균 77.3점을 기록해 오픈AI의 GPT-5 미니(73.5점), 앤트로픽의 클로드 소넷 4.5(74.6점), 알리바바의 큐원3 235B(77.0점)를 앞섰고, 약 330억 개(33B)의 파라미터로 기존 ‘K-엑사원’의 약 7분의 1 크기임에도 동등한 텍스트 이해·추론 성능을 달성했다고 밝혔습니다. LG AI연구원은 엑사원 4.5를 허깅페이스에 오픈 웨이트로 공개해 연구·학술·교육 목적으로 활용 가능하도록 했으며, 이를 K-엑사원의 멀티모달 확장 및 음성·영상·물리 환경을 이해하는 피지컬 인텔리전스 구현의 핵심 기반 모델로 제시했습니다.







![[AI 클로즈업] 엑사원에 눈 달았다…LG AI연구원, 피지컬 AI 레이스 참전](https://www.ddaily.co.kr/photos/2026/04/10/2026041015352957716_l.jpg)

