article detail
이미지·텍스트 동시 파악→추론… LG, 멀티모달 AI '엑사원 4.5' 공개
2026. 4. 9. 오전 10:55

AI 요약
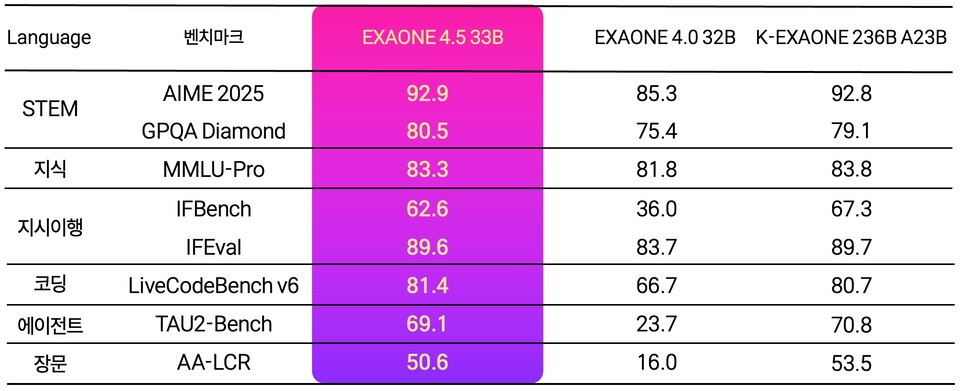
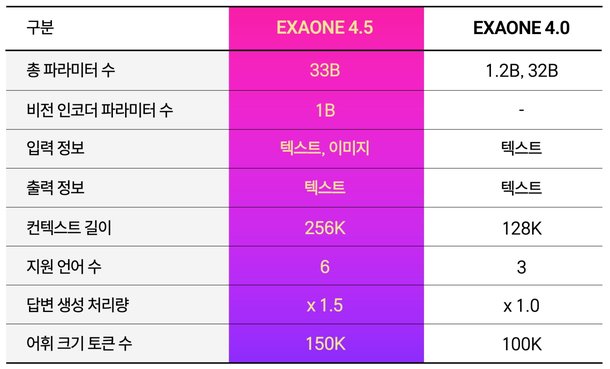
LG AI연구원이 9일 이미지와 텍스트를 동시에 파악하고 추론할 수 있는 비전-언어 모델(VLM) '엑사원 4.5'를 공개했으며, 독자적으로 구축한 비전 인코더와 거대 언어 모델을 결합한 멀티모달 AI로 앞으로 'K-엑사원'의 모달리티 확장을 위한 사전 단계이자 궁극적으로 피지컬 인텔리전스를 지향한다고 밝혔습니다. 엑사원 4.5는 산업 현장의 계약서·재무제표·기술 도면 등 복잡한 서류를 읽는 능력이 탁월하며, 시각 처리와 추론을 가늠하는 13개 지표 평균에서 지피티(GPT)5-mini·클로드 소넷 4.5·큐웬3-VL 등을 앞섰고, STEM 5개 지표 평균 77.3점, 라이브코드벤치 v6 81.4점, ChartQA Pro 62.2점을 기록했습니다. 모델은 약 330억 파라미터 규모로 K-엑사원의 7분의 1 수준이지만 고속 추론 기술과 하이브리드 어텐션을 도입해 동등한 텍스트 이해력을 구현했으며, 한국어·영어·스페인어·독일어·일본어·베트남어 등 6개 언어를 지원하고 허깅페이스에 오픈 웨이트로 공개했으며, 올해 1월부터 동북아역사재단의 데이터를 학습해 한국 고유의 역사와 사회적 맥락 특화 능력을 키우고 있습니다.