article detail
노타, GPU·NPU 역할 분담으로 온디바이스 AI 효율 높인다
2026. 6. 4. 오후 2:12

AI 요약
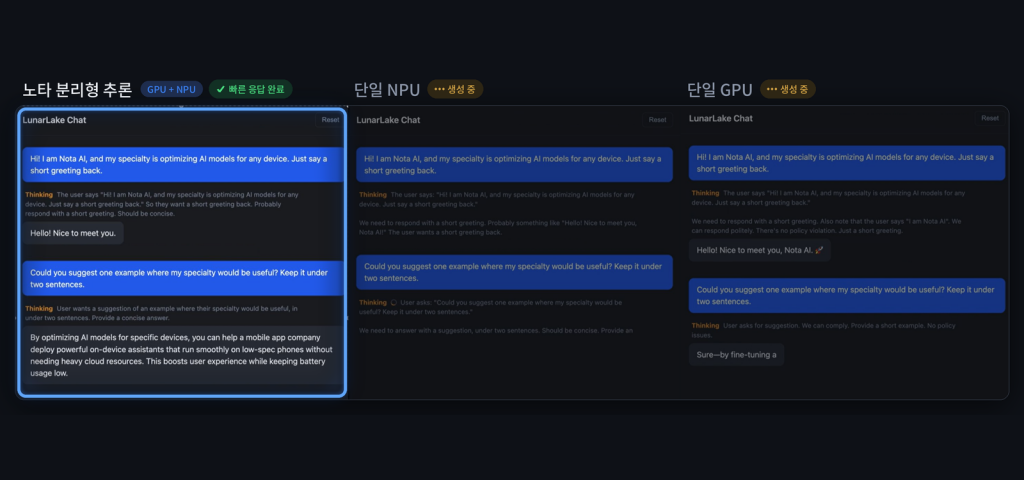
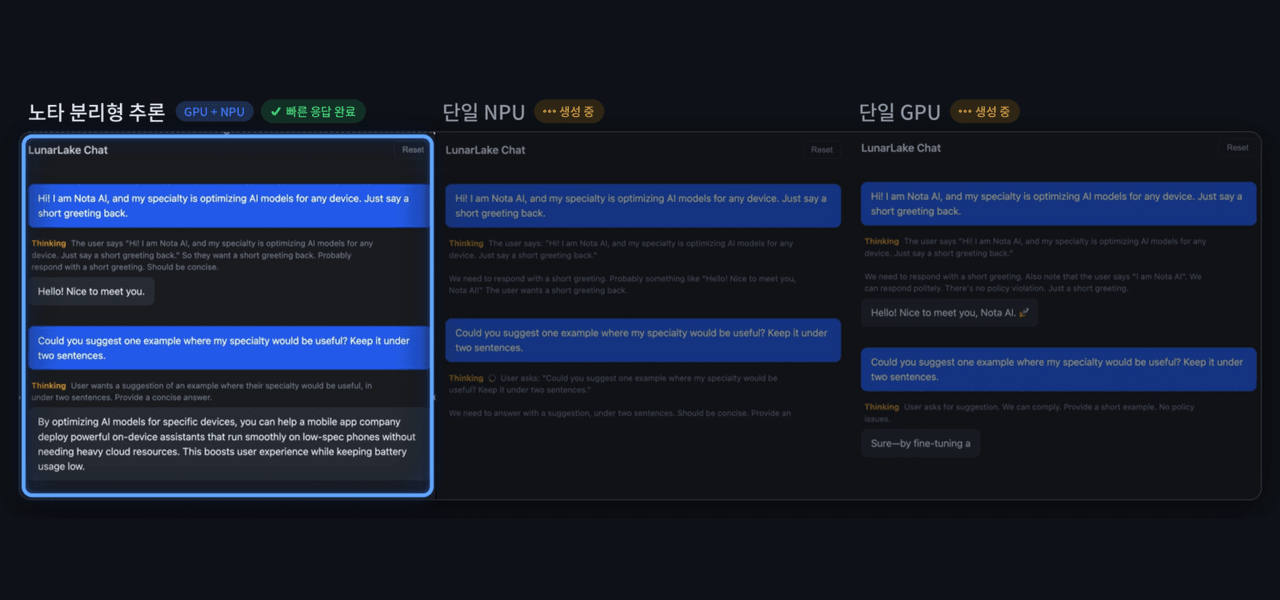
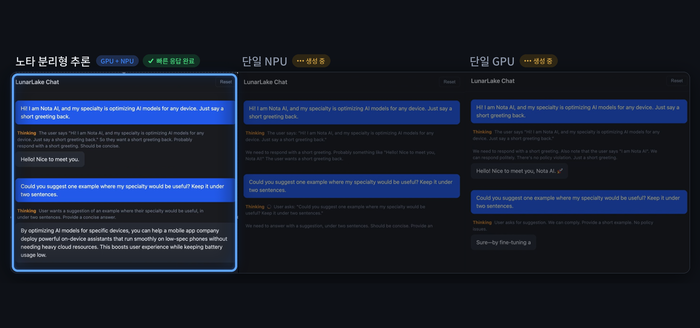
4일 노타는 인텔 '루나 레이크' 기반 AI PC에서 GPU와 NPU를 동시에 활용하는 이기종 컴퓨팅 기반 대규모 언어 모델(LLM) 추론 최적화 기술을 구현하고 추론 과정을 입력 처리와 답변 생성으로 분리하는 '분리형 추론' 방식을 적용했다고 밝혔습니다. 입력과 프롬프트 처리는 병렬 연산 성능이 뛰어난 GPU가, 답변 생성은 전력 효율이 높은 NPU가 담당하도록 분배한 결과 단일 GPU 대비 토큰당 에너지 소비는 약 32% 감소하고 생성 처리량은 약 12% 향상됐으며 단일 NPU 대비 첫 응답 지연은 약 89% 단축됐습니다.
![노타, GPU·NPU 동시 활용 AI 추론 기술 구현에 13%↑[특징주]](https://image.edaily.co.kr/images/Photo/files/NP/S/2026/06/PS26060400382.jpg)
![[테크스냅] AI PC서 GPU·NPU 분산 활용…노타, LLM 추론 효율 높인다](https://thumbnews.nateimg.co.kr/view610///news.nateimg.co.kr/orgImg/yt/2026/06/04/AKR20260604065000017_01_i.jpg)