article detail
노타, 이기종 컴퓨팅 기반 LLM 최적화 구현…"실행효율 제고 노력"
2026. 6. 4. 오전 8:53
AI 요약
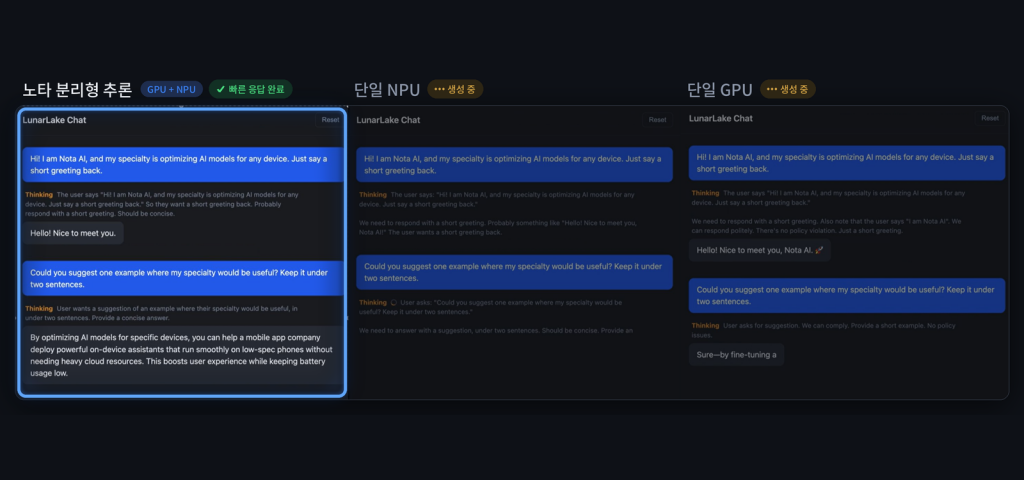
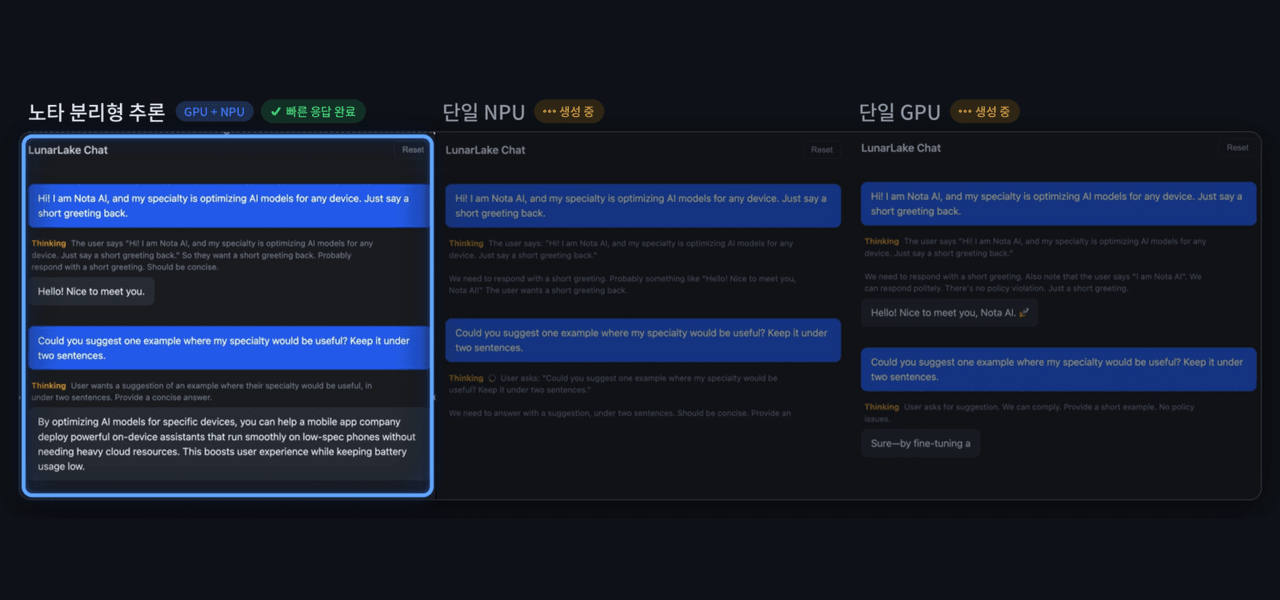
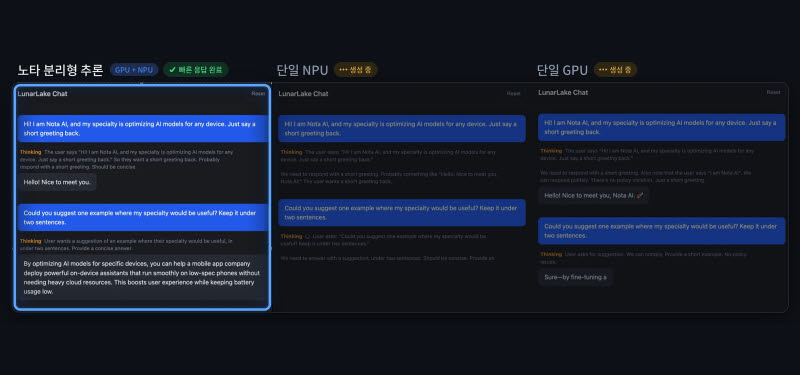
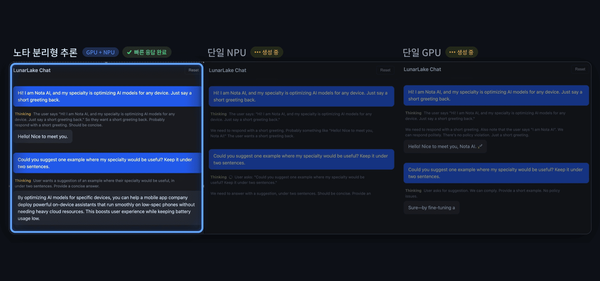
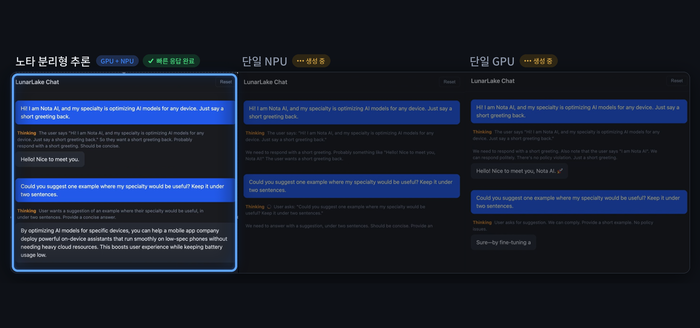
노타가 4일 인텔 루나 레이크(Intel Lunar Lake) 기반 AI PC에서 GPU와 NPU를 함께 활용하는 이기종 컴퓨팅 기반 대형 언어 모델(LLM) 추론 최적화 기술을 구현하고, 입력 처리와 답변 생성 연산을 분리해 각 연산에 적합한 장치에 배치하는 분리형 추론(Disaggregated Inference) 방식을 적용했다고 밝혔습니다. 성능 평가에서 분리형 추론은 단일 GPU 실행 방식 대비 토큰당 에너지 소비를 약 32% 줄이고 생성 처리량을 약 12% 높였으며, 단일 NPU 실행 방식 대비 첫 응답 지연시간을 약 89% 단축했다고 설명했습니다. 노타 채명수 대표는 다양한 연산 장치를 모델 특성에 맞게 조합하는 최적화 역량이 실제 AI 경험을 좌우한다며 모델 경량화·런타임 최적화·하드웨어 최적화 기술을 결합해 온디바이스 AI 실행 효율을 높이겠다고 밝혔습니다.
![[테크스냅] AI PC서 GPU·NPU 분산 활용…노타, LLM 추론 효율 높인다](https://thumbnews.nateimg.co.kr/view610///news.nateimg.co.kr/orgImg/yt/2026/06/04/AKR20260604065000017_01_i.jpg)
![노타, GPU·NPU 동시 활용 AI 추론 기술 구현에 13%↑[특징주]](https://image.edaily.co.kr/images/Photo/files/NP/S/2026/06/PS26060400382.jpg)