article detail
세계 최고 AI 9종 시험 봤더니…200개 과제 완전 정복, 단 하나도 없었다
2026. 5. 12. 오전 8:09
AI 요약
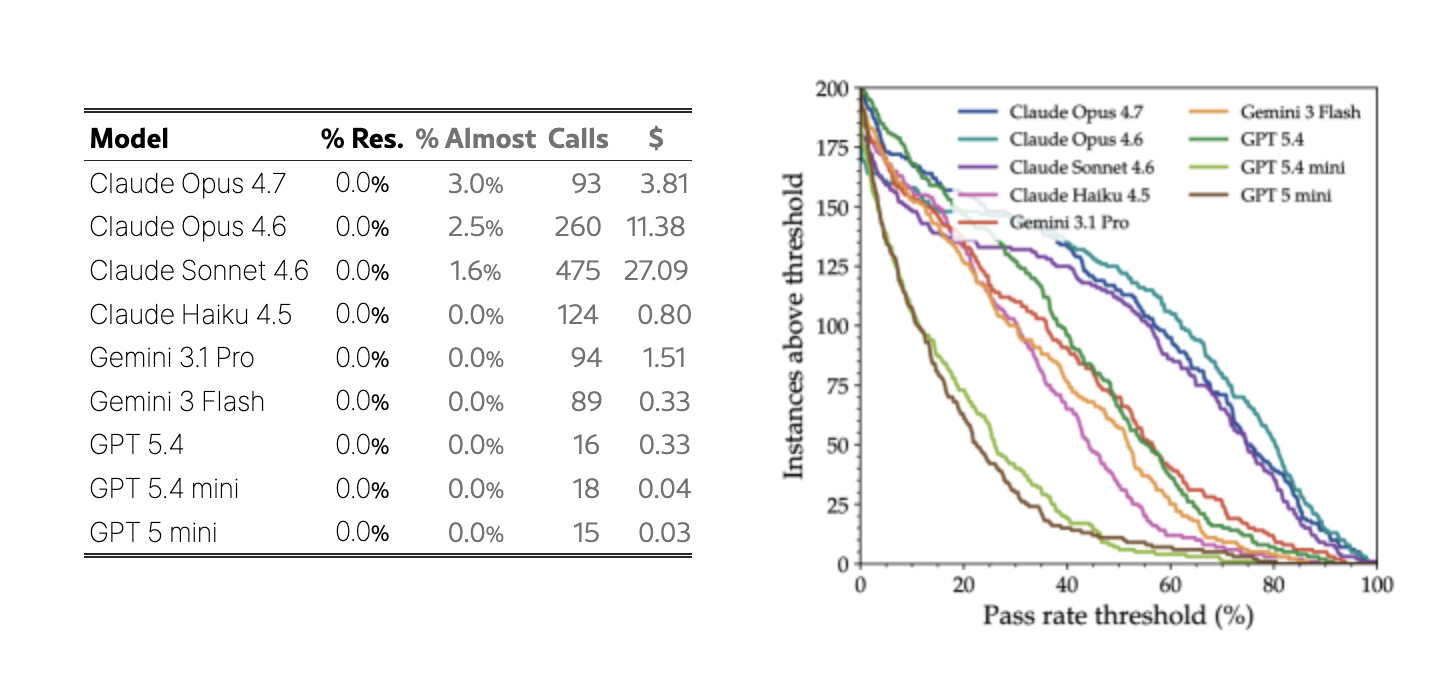
2026년 5월 메타 FAIR·스탠퍼드대·하버드대 공동 연구팀은 프로그램벤치 논문을 공개하고 FFmpeg, SQLite, PHP 인터프리터 등 실제 현장용 프로그램 200종을 소스코드 없이 실행 파일과 사용 설명서만으로 클로드 오퍼스 4.7, GPT-5.4, 제미나이 3.1 프로 등 언어모델 9종으로 시험해 총 24만 8853개의 동작 테스트로 검증했습니다. 결과는 완전 해결율 0%였고 가장 성적이 좋은 모델조차 200개 과제 중 6개 과제에서만 테스트의 95%를 통과했으며 연구팀은 AI가 생성한 코드베이스가 단일 파일 구조로 쏠리고 대형 소프트웨어의 장기적 아키텍처 설계와 모듈 간 조율에 근본적 한계가 있다고 결론지었습니다. 리처드 서튼 교수는 LLM이 모방 기계이고 실질적 목표가 없으며 현장 학습이 불가능하다고 지적했고, 2025년 4월 데이비드 실버와의 논문 등에서 경험 기반(강화학습) 에이전트가 대안임을 제시했습니다.




![[혁신플랫폼톡] AI의 전장이 끊임없이 확대되고 있다](https://img.etnews.com/news/article/2026/06/02/news-p.v1.20260602.28f43f29a8a647c0a0982125cfbc1736_P3.png)

![[기획]"컴퓨터는 끝났다"…젠슨 황 'AI전용 CPU' 공개](https://www.ket.kr/data/photos/20260623/art_17803774082116_ff469a.jpg)

![[미국 특징주] 마이크로소프트, 연례 개발자 콘퍼런스서 PC·클라우드 AI 신기술 공개 예정](https://img.newspim.com/news/2026/04/24/2604240313125270_t1.jpg)