article detail
GPT보다 두 배 정확하게 잡아냈다, AI 에이전트 실수를 미리 막는 '감시자' 등장
2026. 5. 15. 오전 11:39
AI 요약
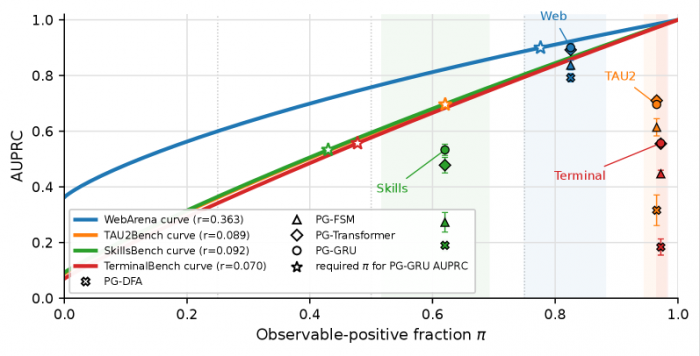
영국 리버풀대학교와 프랑스 그르노블알프대학교 연구진이 2026년 5월 발표한 논문 프리픽스가드(PrefixGuard)에 따르면, 작고 가벼운 학습 모니터가 거대 언어모델(LLM) 판사보다 AI 에이전트 실패 예측을 최대 두 배 가까이 더 정확하게 수행했습니다. 프리픽스가드의 최고 모니터는 WebArena·τ2-Bench·SkillsBench·TerminalBench에서 각각 0.900, 0.710, 0.533, 0.557의 AUPRC를 기록했고, 같은 환경에서 GPT-5.4-mini와 DeepSeek V4-Pro는 최고 0.407과 0.450에 그쳤으며, 핵심 기법으로 실행 기록을 일곱 항목으로 표준화하는 스텝뷰(StepView)와 주로 GRU 백엔드의 소규모 학습이 사용되었습니다. 다만 AUPRC가 높다고 해서 실제 경보 시스템으로서 효과적인 것은 아니어서, WebArena는 0.900 AUPRC에도 거짓 경보율을 10% 이하로 묶었을 때 실패 작업의 28.7%만 사전에 잡아냈고 경보도 작업 종료 직전에 울렸던 반면 τ2-Bench는 0.710 AUPRC로도 실패 작업의 97.9%를 조기에 잡아냈습니다.



![AI가 AI를 낳는다…LLM 넘어 '재귀적 자기 개선'으로 [테크토크]](https://img1.daumcdn.net/thumb/S1200x630/?fname=https://t1.daumcdn.net/news/202606/06/akn/20260606072902145vbbk.png)

![AI가 AI를 낳는다…LLM 넘어 '재귀적 자기 개선'으로 [테크토크]](https://thumbnews.nateimg.co.kr/view610///news.nateimg.co.kr/orgImg/ae/2026/06/06/ae_1780698424437_679379_0.png)

![AI가 AI를 낳는다…LLM 넘어 '재귀적 자기 개선'으로 [테크토크]](https://cphoto.asiae.co.kr/listimglink/1/2026060114125083910_1780290769.png)


