article detail
[개발] 글자·사진·소리·영상 동시에 이해하고 만드는 차세대 통합 AI 파운데이션
2026. 4. 13. 오전 9:11
![[개발] 글자·사진·소리·영상 동시에 이해하고 만드는 차세대 통합 AI 파운데이션](https://elec4.co.kr/media/commonfile/202604/13/d3e665bd4817c0c6a5d801ff115cd26e.jpg)
AI 요약
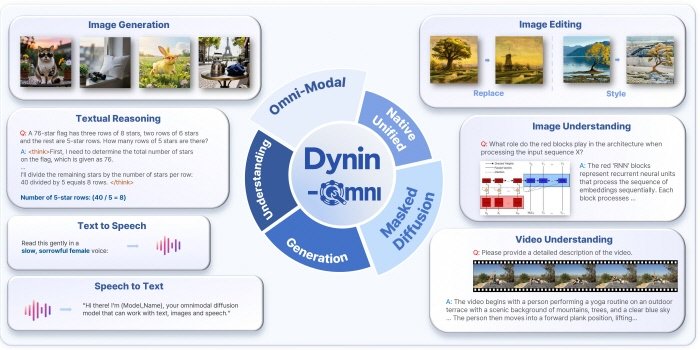
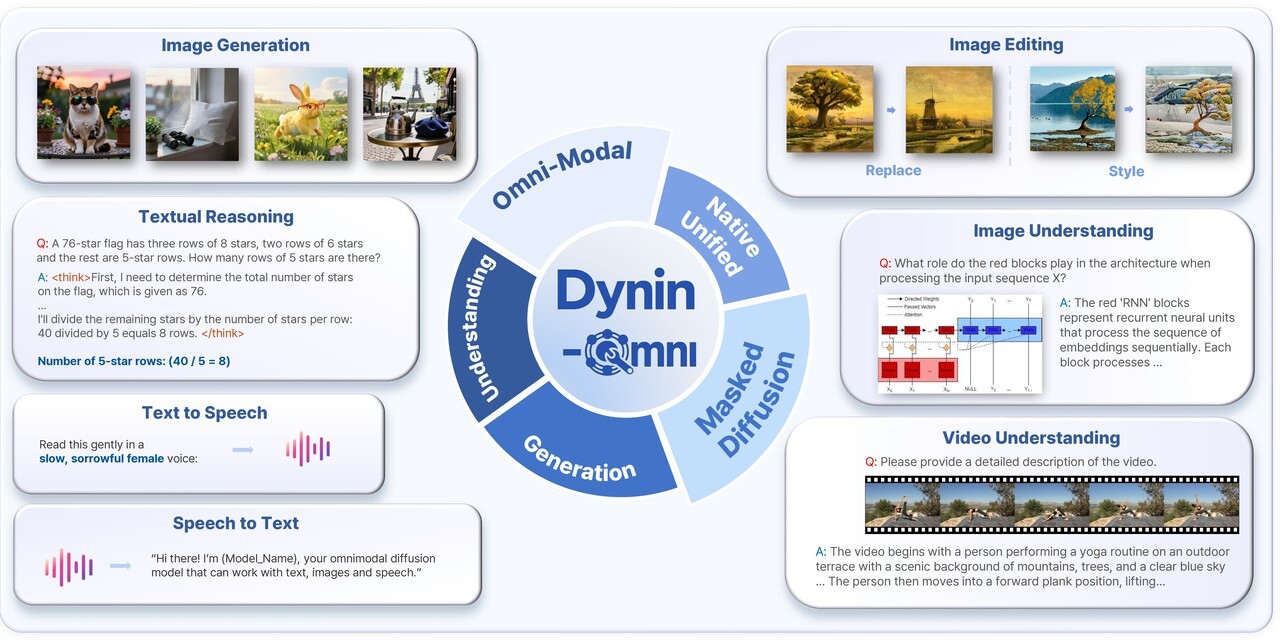
서울대학교 공과대학 전기정보공학부 도재영 교수 연구팀(AIDAS 연구실)이 글자, 사진, 영상, 소리를 하나의 모델이 동시에 이해하고 생성할 수 있는 차세대 AI 파운데이션 모델 Dynin-Omni를 개발했다고 밝혔습니다. 이 모델은 모든 정보를 동일한 기준으로 통합해 처리하고 디퓨전 방식으로 결과물 전체를 한꺼번에 생성하며 이해와 생성 기능을 하나로 합쳐 기존의 순차적 생성 방식 문제를 해결했다고 연구진은 설명했습니다. Dynin-Omni는 총 19개의 글로벌 AI 성능 지표 평가에서 기존 통합 모델들을 앞섰고 특정 분야 전문가용 모델과 견줄 만한 성능을 보였으며 기존 통합 AI 모델 대비 최대 4~5배 빠른 생성 속도를 구현해 로봇, AI 비서, 스마트 기기 등에서 활용될 것으로 기대된다고 학교 측은 밝혔습니다.


![[굿!디자인] LVMH도 인정한 패션AI...엔엑스엔랩스](https://img.etnews.com/news/article/2026/05/28/news-p.v1.20260528.aeeebc25627349008745ebec546eaae7_P1.png)

![[AI 뉴스] 구글, ‘제미나이 3.5·스파크·옴니’ 전격 공개… AI 운영 생태계 전면 재편](https://cdn.outsourcing.co.kr/news/photo/202605/202745_54230_160.png)