article detail
"글자부터 영상까지 ‘올인원’ 옴니모달 AI, 세계 최초 구현"..서울대 도재영 교수팀, 통합 AI 파운데이션 모델 개발
2026. 4. 7. 오전 10:14

AI 요약
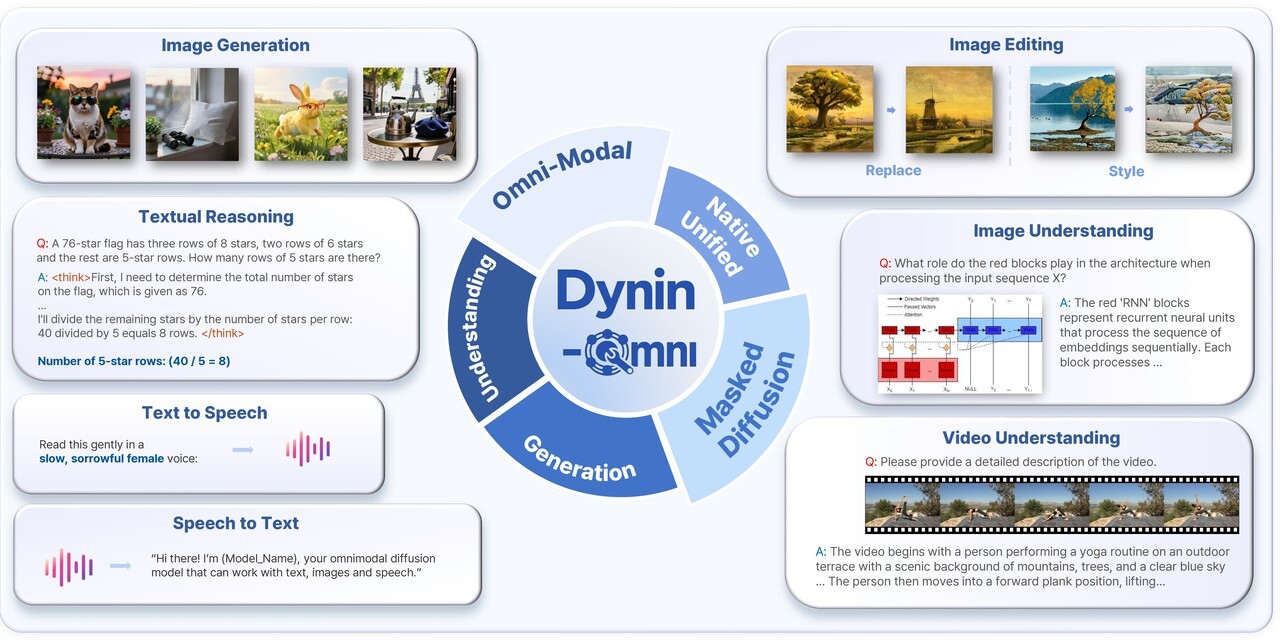
서울대학교 공과대학 전기정보공학부 도재영 교수 연구팀(AIDAS 연구실)은 글자·사진·영상·소리를 하나의 모델이 동시에 이해하고 생성할 수 있는 차세대 파운데이션 모델 '다이닌 옴니(Dynin-Omni)'를 개발했다고 7일 밝혔습니다. 연구진은 모든 감각 정보를 공통 언어 공간으로 통합 처리하는 완전 통합 옴니모달 구조와 결과물 전체를 한꺼번에 생성하는 디퓨전 방식, 이해와 생성 기능을 하나의 모델로 결합한 설계로 변환 과정 없이 다양한 형태의 정보를 동시에 처리하고 처리 속도를 높였다고 설명했습니다. Dynin-Omni는 총 19개의 글로벌 벤치마크에서 기존 통합 모델들을 앞지르고 특정 분야 전문 모델과 유사한 성능을 보였으며 기존 통합 모델 대비 최대 4~5배 빠른 생성 속도를 구현해 로봇·AI 비서·스마트 기기 등 피지컬 AI 분야에 활용될 것으로 연구진은 기대했습니다.
![[개발] 글자·사진·소리·영상 동시에 이해하고 만드는 차세대 통합 AI 파운데이션](https://elec4.co.kr/media/commonfile/202604/13/d3e665bd4817c0c6a5d801ff115cd26e.jpg)



![[굿!디자인] LVMH도 인정한 패션AI...엔엑스엔랩스](https://img.etnews.com/news/article/2026/05/28/news-p.v1.20260528.aeeebc25627349008745ebec546eaae7_P1.png)





