article detail
[매경의 창] LLM 혁명의 새 슈퍼갑 '메모리'
2026. 4. 9. 오후 5:03
![[매경의 창] LLM 혁명의 새 슈퍼갑 '메모리'](https://pimg.mk.co.kr/news/cms/202604/10/20260410_01160130000001_M00.jpg)
AI 요약
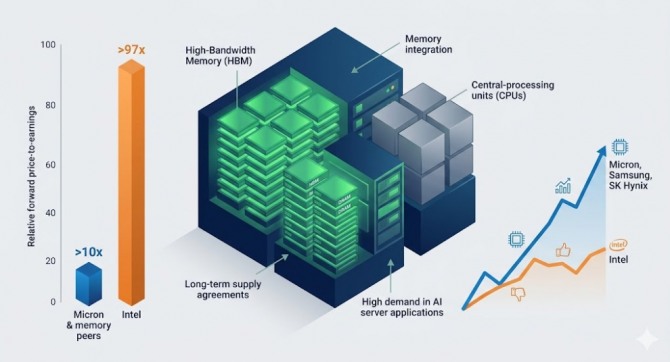
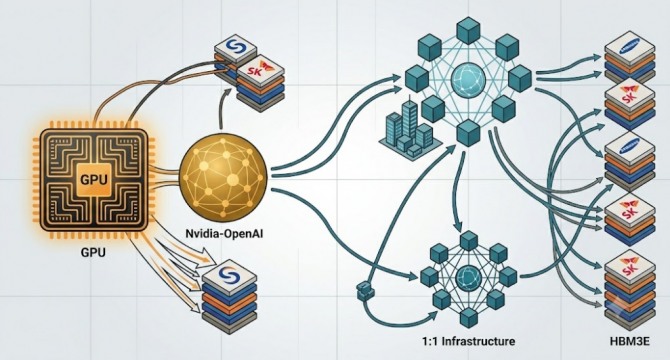
대규모언어모델(LLM)은 긴 토큰 서열을 처리할 때 연산보다 GPU의 HBM과 SRAM 사이 데이터 이동에 대부분의 시간이 소모되며, 기사에는 H100 GPU의 SRAM이 75MB, HBM은 대개 100GB로 HBM이 SRAM보다 수백 배 느리다고 설명되어 있습니다. KV 캐싱은 블록 계산 결과를 HBM에 저장해 반복 계산을 줄임으로써 수만 배의 속도 개선을 가져올 수 있지만 데이터 이동이 전체 수행 시간의 99% 이상을 차지할 수 있고, 구글의 터보퀀트처럼 표현 비트를 약 4분의 1로 줄이는 기술은 HBM 사용을 줄여 수용자를 늘리나 압축 해제 비용으로 속도 개선은 미미하다고 했습니다. 문병로 교수는 HBM 병목으로 메모리 수요가 커지며 삼성이 메모리 우위로 부상해 늦어도 내후년에는 삼성전자의 영업이익이 엔비디아를 넘어설 것이라고 전망했으며, 기사에 따르면 어제 기준 엔비디아의 시가총액은 6500조원, 삼성전자는 1200조원입니다.
![[매경의 창] LLM 혁명의 새 슈퍼갑 '메모리'](https://img1.daumcdn.net/thumb/S1200x630/?fname=https://t1.daumcdn.net/news/202604/09/mk/20260409192705544szsm.jpg)

![[컴퓨텍스 2026] 결산 ㊤ `PC 부품 메카`서 `AI 실전 무대`로… 타이베이 휩쓴 `K-반도체`](https://www.ddaily.co.kr/photos/2026/06/04/2026060412282165028_l.JPG)


![엔비디아는 왜 PC용 칩을 만드나 [AI칩 인사이드]](https://assets.mtn.co.kr/mtn/2026/06/PG3nloG4YoQUkWQS/image/20260601_164810//c35409fe2102108672d291301a2584d35e28612332d474d2536dd166c07c18e6.jpg)